Close the loop: analytics that teach your chatbot to fix itself
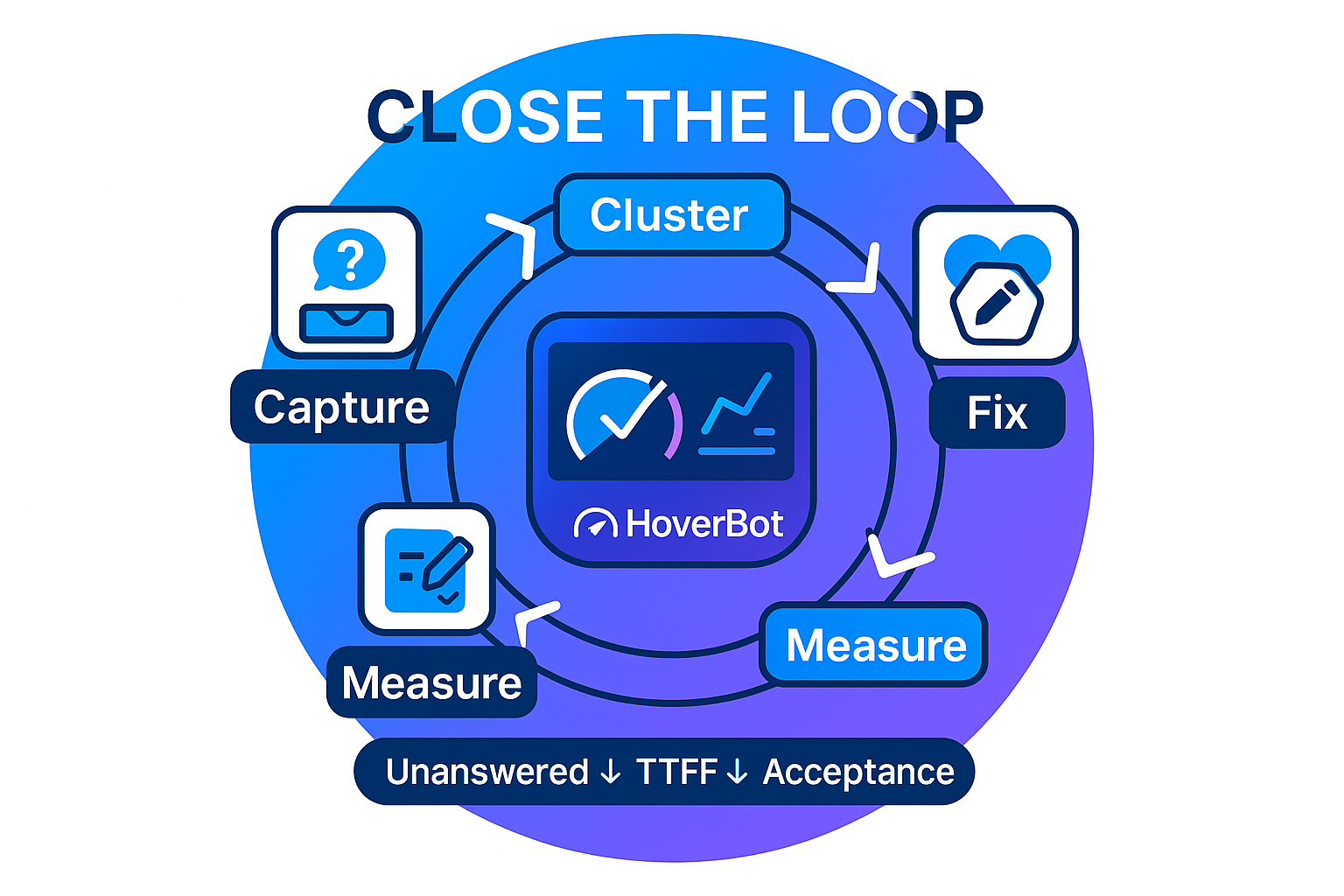
Start with lean instrumentation
Analytics only works if the trail is short and consistent. Capture the user message, the decision the assistant made, the sources it consulted, the final answer, and any fallback it used. Record time to first token and time to full answer. This gives a clear picture of what happened and why. Long logs feel thorough but slow teams down. A compact record gets read and acted on.
Define unanswered with clear rules
- The question is in scope and relevant, yet the reply has no supporting citation or source
- A fallback was needed to finish the turn such as clarify, retrieve, or hand off
- Confidence is below your threshold or the reply uses hedging language like "not sure" or "I think"
- The user reasks the same thing within a short window
- Retrieval returns nothing useful or cannot locate the expected document
- The reply conflicts with the current knowledge base
Do not count out of scope or non relevant messages as unanswered. Those belong to the guardrail stream. Use one rule set across teams so the dashboard stays trusted.
What guardrails really are
Guardrails are the decision layer that determines whether a request should be answered, how it should be answered, or declined. They protect scope, safety, policy, and data hygiene before the model spends tokens. They can be rules, a policy engine, an ML classifier, or a hybrid.
Keep them alive by sampling borderline cases each week, correcting mistakes, adding examples, and tracking false blocks and false allows so thresholds stay fair.
Separate noise from real gaps
Not every miss deserves work. First filter out non relevant items such as spam, off topic questions, and test phrases. These belong to guardrail improvement. Then focus on relevant but unanswered questions. These are in scope, they matter to users, and they did not receive a grounded answer. This is the signal that drives action.
Run a weekly improvement loop
Set a steady rhythm. Review the unanswered queue once a week. Group similar questions into clusters. Choose a remedy for each cluster. If the assistant should not answer, strengthen guardrails and improve the decline message. If the assistant should answer, add a short article or update the knowledge that powers retrieval.
Publish each change with a one line note on what moved and why. Check the same clusters the next week to confirm they dropped. The goal is movement, not perfection.
Keep ownership tight
Assign a single owner for each stream and metric. Product owns unanswered rate and time to first fix. Content owns missing or stale knowledge. Engineering owns guardrails, routing, and fallbacks. Keep the meeting short by design.
Make privacy part of the loop
Analytics does not need raw personal data. Mask names and identifiers before storage. Keep customers separated by tenant. Set a retention window that matches policy and delete on schedule. Log who viewed and who changed what.
Measure what leaders care about
A focused dashboard keeps attention on outcomes. Put these on the top row:
- Unanswered rate
- Time to first fix
- Acceptance rate
Add flow and coverage next:
- Route mix
- Retrieval coverage
- Average latency
Starter targets
- Unanswered under 10 percent within four weeks
- Time to first fix under 72 hours at the median
- Acceptance above 70 percent for in scope intents
What good looks like after a month
The same gaps no longer dominate the board. New questions appear but old ones retire. Unanswered trends down and stays down. Stakeholders can point to specific changes shipped that week and the effect on top clusters. The assistant stays within its lane and explains its limits without friction. Users get to outcomes faster because the system keeps learning from misses.
Weekly loop agenda
- Review top line metrics for five minutes
- Open the unanswered queue
- Cluster similar questions
- Decide fix for each cluster
- Assign owner and date
- Publish a one line change log
- Confirm next week that the cluster dropped
How HoverBot applies these principles
HoverBot follows the same basics with a loop that is easy to run. Each turn is logged with a start, a decision, and an outcome. The system separates non relevant messages into the guardrail stream and groups relevant unanswered questions into clusters.
Owners receive clear queues. Product sees unanswered and time to first fix. Content sees proposed knowledge items with example questions. Engineering sees routing outliers and fallbacks that fire too often.
Every change is tagged and linked back to the cluster that triggered it. Privacy is handled by default. Personal data is masked. Tenants are isolated. Retention is configurable and deletions are real.
About the author
HoverBot TeamAI Product Engineering Team
Cross-functional team of AI engineers, product managers, and support operators building customer-facing chatbot systems in production environments. We ship weekly releases informed by production telemetry, closed-loop conversation reviews, and benchmark-driven evaluation cycles.
- Customer support automation and intelligent routing systems
- RAG pipeline design and guardrails for regulated workflows
- Operational analytics and closed-loop quality improvement
- Multilingual NLP and entity-level PII masking pipelines
- Production deployments across e-commerce, real estate, and SaaS verticals
Share this article
Related Articles
Routing Beats Bigger Models: A Production Architecture
GPT-4o costs 15x more than GPT-4o-mini. Claude Opus costs 30x more than Haiku. The question is not which model to use. The question is which model to use for each request. A smart router cuts cost 70% while improving quality.
How chatbots remember: short term, long term and everything in between
Product teams are adding memory to AI assistants to improve continuity and personalization. Memory is not a single feature but a layered system. Designed well, it lifts resolution and trust. Designed poorly, it creates drift, privacy risk and cost.