Routing Beats Bigger Models: A Production Architecture
The expensive mistake everyone makes
Teams building chatbots pick one model and route everything through it. "We need the best quality, so we'll use GPT-4o." Then they get the bill. Then they switch to a cheaper model. Then quality drops. Then they wonder if AI chatbots actually work.
The mistake is treating model selection as a single decision instead of a per-request decision. Look at real chatbot traffic:
- 40% is social fluff: "hi", "thanks", "ok", greetings, acknowledgments. No reasoning required. A template response works.
- 30% is simple lookup: "what are your hours", "where is my order", "what's your return policy". One retrieval hit, template response. GPT-4o-mini handles this perfectly.
- 20% is moderate complexity: Multi-step questions, comparisons, recommendations. Needs reasoning but not frontier capability.
- 10% is genuinely hard: Complex synthesis, nuanced judgment, creative problem-solving. This is where frontier models earn their cost.
If you route 100% of traffic through GPT-4o, you're paying frontier prices for "thanks" and "ok". A router that sends each request to the right model cuts cost 70% without touching the hard 10%.
The math that should change your architecture
| Traffic Type | % of Requests | Best Route | Cost/1K requests |
|---|---|---|---|
| Social (hi, thanks) | 40% | Template + tiny model | $0.002 |
| Simple lookup | 30% | RAG + GPT-4o-mini | $0.04 |
| Moderate complexity | 20% | RAG + Claude Sonnet | $0.45 |
| Genuinely hard | 10% | RAG + GPT-4o/Opus | $1.50 |
Cost Comparison
- With routing: ~$0.28/1K requests (blended average)
- GPT-4o everywhere: ~$1.50/1K requests
- Savings: 81%
Numbers assume ~500 tokens/request average. Your mileage varies based on conversation length and complexity distribution.
These numbers are illustrative but directionally correct. The exact savings depend on your traffic distribution and model choices. The principle holds: route to the cheapest model that can handle each request.
Current model pricing landscape
Model pricing changes frequently. As of early 2026, here is the landscape for chat-oriented models:
| Model | Input $/1M tokens | Output $/1M tokens | Best For |
|---|---|---|---|
| GPT-4o-mini | $0.15 | $0.60 | Simple lookups, FAQ, high volume |
| Claude 3.5 Haiku | $0.80 | $4.00 | Fast responses, moderate reasoning |
| Claude 3.5 Sonnet | $3.00 | $15.00 | Complex reasoning, nuanced responses |
| GPT-4o | $2.50 | $10.00 | Complex reasoning, broad knowledge |
| Claude 3 Opus | $15.00 | $75.00 | Most complex tasks only |
Prices as of January 2026. Check vendor pricing pages for current rates.
The price spread is enormous. GPT-4o-mini is 17x cheaper than GPT-4o per input token. Claude Haiku is 19x cheaper than Opus. This spread is your leverage.
The three-lane architecture
Every request enters the router and gets classified into one of three lanes:
Lane 1: Safety (always runs first)
Local classifiers check for PII, policy violations, and out-of-scope requests. This lane runs before anything leaves your infrastructure. No tokens spent on external models. No data leakage.
The safety lane handles:
- PII detection and masking (see our PII patterns post)
- Scope checking: is this question in-bounds for this chatbot?
- Policy enforcement: blocked topics, required disclosures
- Rate limiting and abuse detection
Lane 2: Fast (cheap, local, instant)
Social turns, simple acknowledgments, and template responses. A tiny model or even rule-based responses. Latency under 100ms. Cost near zero.
What goes in the fast lane:
- Greetings: "hi", "hello", "hey there"
- Acknowledgments: "thanks", "ok", "got it"
- Simple confirmations: "yes", "no", "sure"
- Closings: "bye", "that's all", "nothing else"
These can be handled with templates or a tiny local model. No need to call GPT-4o for "thanks".
Lane 3: Heavy (expensive, powerful, necessary)
Complex questions that require synthesis, reasoning, or nuanced judgment. RAG retrieval plus a frontier model. This is where you spend money, so make every request count.
What goes in the heavy lane:
- Multi-step reasoning: "Compare X and Y considering A, B, C"
- Nuanced judgment: "Should I choose option A or B for my situation?"
- Creative synthesis: "Summarize these three documents and identify conflicts"
- Edge cases where confidence is low
The router decision logic
The router scores each request on three dimensions and picks the cheapest lane that can handle it:
Scoring Dimensions
- Complexity (0-1): How hard is this question? Based on message length, entity count, question structure, presence of comparisons or conditionals.
- Sensitivity (0-1): How sensitive is the topic? Financial advice, health, legal topics score higher.
- Confidence (0-1): How sure are we about the classification? Low confidence triggers escalation to a safer lane.
// Simplified routing logic
function route(message: string): Lane {
const safety = checkSafety(message);
if (safety.blocked) return Lane.BLOCKED;
if (safety.piiDetected) maskPII(message);
const scores = classify(message);
// Low complexity + high confidence = fast lane
if (scores.complexity < 0.3 && scores.confidence > 0.8) {
return Lane.FAST;
}
// High sensitivity = always heavy lane with guardrails
if (scores.sensitivity > 0.7) {
return Lane.HEAVY_GUARDED;
}
// Moderate complexity = mid-tier model
if (scores.complexity < 0.6) {
return Lane.MID;
}
// Everything else = heavy lane
return Lane.HEAVY;
}Why not just use MCP and let the model decide?
Model Context Protocol is seductive. Give the model tools, let it figure out when to use them. Ship faster, write less code.
In production, MCP creates problems:
- Non-deterministic behavior: The same request can trigger different tool calls depending on prompt variations, model versions, and even load. This makes debugging a forensics exercise.
- Cost unpredictability: A model that decides to call tools can burn through tokens exploring options. You cannot budget what you cannot predict.
- Security surface: Tool parameters are model outputs. Model outputs can be manipulated. Every MCP tool is an injection surface.
- Audit complexity: "Why did the bot call this API?" becomes impossible to answer reliably when the model made the decision implicitly.
Our position: Use MCP for low-stakes exploration and prototyping. Use explicit routing for production. You want deterministic, auditable, predictable systems when real users and real money are involved.
Composite requests: when one message needs multiple lanes
Real user messages are often composite. "What's your return policy, and can you cancel order #4832?" This needs two different processing paths:
- "What's your return policy" → FAQ lookup → fast/mid lane
- "cancel order #4832" → action with parameters → deterministic action lane
Decompose the request, route each segment appropriately, then compose the final response. This adds latency but ensures each part gets the right treatment.
// Composite request handling
const segments = decompose(message);
// ["What's your return policy", "can you cancel order #4832"]
const results = await Promise.all(
segments.map(seg => routeAndProcess(seg))
);
// [FAQ result, Order cancellation result]
const response = compose(results);
// Natural language combining both answersOperational metrics that matter
Traffic Distribution
- Lane mix: What percentage hits each lane? Healthy systems see 60-70% in fast/mid lanes. If most traffic hits heavy, your classifier needs tuning.
- Model mix: Which models are handling traffic? Track this to catch configuration drift.
- Fallback rate: How often does a fast-lane attempt fail and escalate to heavy? Should be under 5%.
Quality Signals
- Resolution rate by lane: Are fast-lane responses actually resolving user needs? If resolution drops, you're routing too aggressively.
- Re-ask rate: How often do users ask the same question again after a fast-lane response? High re-ask = wrong lane.
- Human handoff rate by lane: Which lane is generating the most escalations? Target: heavy lane should have lowest handoff rate.
Cost and Latency
- Cost per request by lane: Track this weekly. If your "cheap" lane is getting expensive, investigate.
- P50/P95 latency by lane: Fast lane should be under 200ms p95. Heavy lane under 3s p95.
- Token efficiency: Tokens per resolved conversation, not per message. This is the metric that matters for cost.
Implementation checklist
- ☐ Deploy local classifiers for PII, scope, and intent detection
- ☐ Build template responses for greetings and acknowledgments
- ☐ Set up complexity scoring based on message length, entity count, question structure
- ☐ Configure model tiers: template → tiny → mid → frontier
- ☐ Implement fallback logic: fast → heavy when confidence drops
- ☐ Add request decomposition for composite messages
- ☐ Log every routing decision with scores and reasons
- ☐ Build dashboards for lane mix, cost, and quality metrics
- ☐ Set up A/B testing infrastructure for routing changes
- ☐ Define per-tenant and per-lane token budgets with alerts
The HoverBot approach
We run a four-layer router:
- Safety layer: Local classifiers for PII masking, scope checking, and policy enforcement. Runs before any external call. Adds 5ms p50.
- Social layer: Template responses for greetings, thanks, acknowledgments. Zero tokens, sub-10ms latency. Handles 35-40% of traffic.
- Knowledge layer: RAG with GPT-4o-mini for straightforward lookups. Most substantive traffic lands here. 150ms p50.
- Reasoning layer: Frontier models for complex synthesis. Reserved for the genuinely hard 8-12%. 800ms p50.
We log every routing decision. We review misroutes weekly. We promote patterns from expensive lanes to cheaper lanes as we identify them. The router gets smarter over time.
We do not use MCP in production chatbot flows. The unpredictability is not worth the convenience.
The opinionated take
The industry is obsessed with bigger models. "GPT-5 will fix everything." "Claude 4 will be so good we won't need routing."
This is wishful thinking. Bigger models cost more. The math does not change. Even if GPT-5 is 10x better, you still do not want to pay frontier prices for "thanks" and "ok".
Three realities the industry ignores:
- Traffic distribution is stable. Most chatbot interactions are simple. This will not change because human communication patterns do not change. Social greetings, simple questions, and acknowledgments will always dominate.
- Price gaps persist. Even as models improve, there will always be cheaper models that handle simple tasks well. The price spread between tiers persists because it reflects real capability differences.
- Latency matters for simple queries. Users asking "what are your hours" do not want to wait 2 seconds for GPT-4o to think about it. A fast path improves UX independent of cost.
Routing is not a hack to save money while we wait for better models. Routing is the architecture. It is how you build systems that are fast, cheap, and good at the same time. It is how you build systems that improve over time by learning which patterns can be handled cheaply.
The teams that understand this are building sustainable AI products. The teams that don't are burning money and wondering why their unit economics never work.
Build the router.
About the author
HoverBot TeamAI Product Engineering Team
Cross-functional team of AI engineers, product managers, and support operators building customer-facing chatbot systems in production environments. We ship weekly releases informed by production telemetry, closed-loop conversation reviews, and benchmark-driven evaluation cycles.
- Customer support automation and intelligent routing systems
- RAG pipeline design and guardrails for regulated workflows
- Operational analytics and closed-loop quality improvement
- Multilingual NLP and entity-level PII masking pipelines
- Production deployments across e-commerce, real estate, and SaaS verticals
Share this article
Related Articles

Why Building a Customer Facing Chatbot Is Hard (and How to Fix It)
The hardest part is not the model, it is the human layer. Learn how to detect social intent, run guardrails, ground answers with retrieval, and use confidence gates to build chatbots that sound human, not robotic.
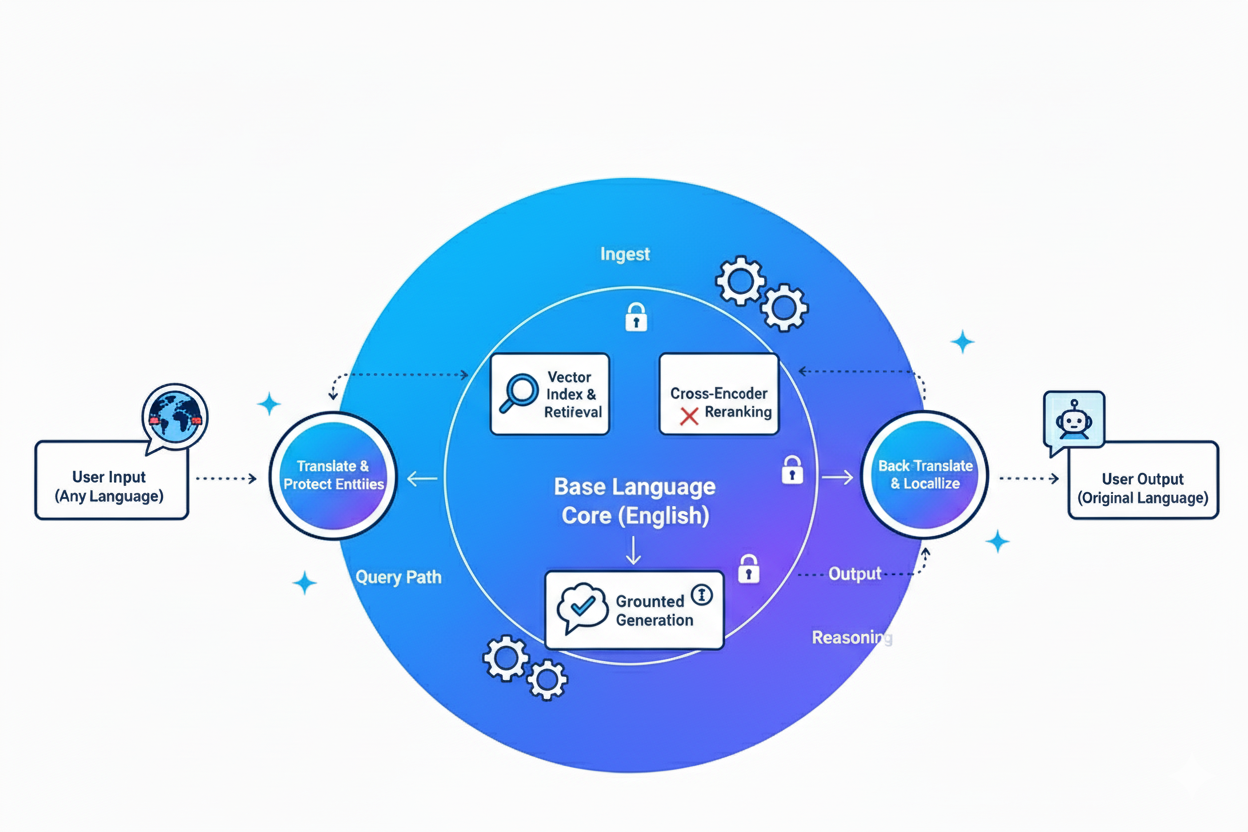
Multilingual RAG Architecture That Works in Production
A battle-tested architecture for multilingual RAG: translate at the edges, reason in one base language, and protect entities throughout. Includes chunking strategies for CJK scripts, embedding model benchmarks, and the metrics that matter.