February Felt Like Living in the Future
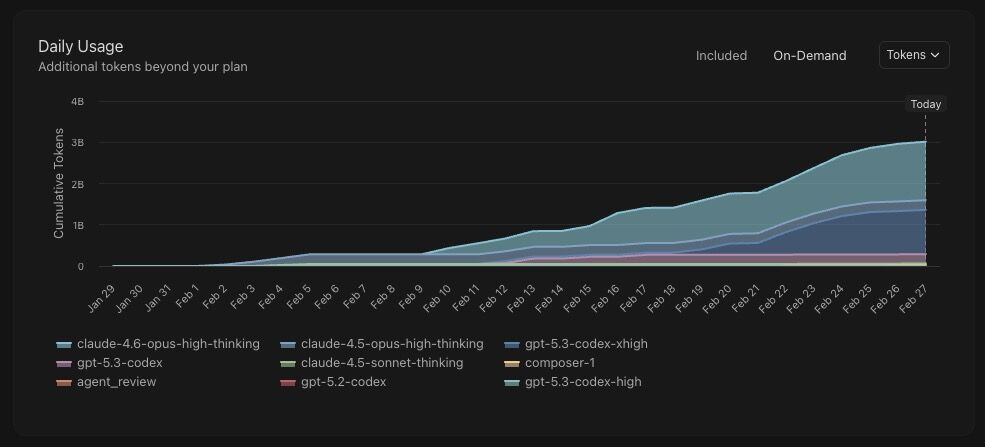
We used about 3 billion tokens in a single month across Claude Opus and GPT Codex runs. A few more stats from the same sprint:
- 86 commits
- 30 releases (v0.0.26 to v0.0.55)
- Net +122,000 lines of code
The output numbers are interesting, but the real story is process maturity. We moved from "ship fast and test later" to a repeatable engineering loop where every meaningful feature goes through an agent based end to end verification step before release.
What changed in testing
We stopped thinking only in terms of "write unit tests" and started running true end to end tests with Codex models: real flows, real clicks, and realistic data states.
Instead of manually writing dozens of brittle browser scripts first, we describe product intent and acceptance criteria, then let agents generate and execute flow coverage, report failures with traces, and propose patches. Engineers keep the final review and merge authority.
Our practical end to end testing loop
- Define the scenario: what the user is trying to do, what success looks like, and key limits like privacy and latency.
- Generate test flows: the agent creates both normal flows and tricky edge cases, using recent bugs as input.
- Run on staging: execute tests in an environment that looks like production, with realistic seeded data.
- Capture failures clearly: save screenshots, logs, network calls, and a step by step reproduction path.
- Suggest fixes: the agent proposes patches, and engineers pick and validate the final version.
- Lock in the lesson: each new bug becomes a permanent regression test.
This cut "cannot reproduce" back and forth. Every failed flow came with enough context to debug quickly, not just a red status.
Where this is technically better than unit test only strategy
- Bugs across boundaries: catches issues spanning user interface state, application programming interface contracts, authentication, and asynchronous jobs.
- Product interaction: validates model behavior under actual app state, not isolated prompt tests.
- Data realism: surfaces edge cases from messy datasets, stale cache states, and inconsistent user inputs.
- Release confidence: verifies workflows the same way users actually experience them.
Unit tests still matter for pure logic, deterministic transformations, and critical business rules. But for agentic products, relying on unit tests alone gives a false sense of safety because many production failures happen in integration boundaries.
What made the system stable
- Deterministic fixtures: each test run starts from a known baseline state.
- Environment parity: staging includes the same critical services and feature flags as production.
- Structured artifacts: every failure stores trace IDs, snapshots, and repro summaries for fast debugging.
- Budget controls: token quotas per suite prevent runaway cost while preserving high quality coverage.
- Regression memory: once a bug appears, it becomes part of the permanent flow library.
One practical suggestion
If you have not tried it yet, buy Claude Code Max (or a couple of max plans) and spend one week building with no limits.
Let the agent do the boring parts: scaffolding, test generation, flow execution, and obvious fix proposals. Keep humans on product decisions, architecture, risk review, and final merge responsibility.
The net result is not just more code shipped. It is a tighter feedback loop between product intent, real world behavior, and release quality.
About the author
Vitaly GoncharenkoFounder & CEO at HoverBot
Leads product strategy and applied AI architecture at HoverBot. Over 10 years of experience in software engineering, with deep focus on conversational AI, production ML systems, and safety-first automation. Previously built and scaled customer-facing platforms across e-commerce, fintech, and SaaS. Hands-on with architecture decisions, deployment operations, and benchmark-driven quality optimization.
- 10+ years of software engineering and product architecture
- Applied AI: conversational systems, RAG pipelines, and safety controls
- Production ML deployment, monitoring, and reliability operations
- Benchmark-driven chatbot performance optimization
- Cross-industry experience: e-commerce, fintech, SaaS, real estate
- Published author on AI chatbot architecture and deployment patterns
Share this article
Related Articles
Six Months with AI Agents as Our Development Team
How we handed HoverBot's repo to AI agents and transformed our engineering workflow with specialized ML, backend, frontend, DevOps, and QA agents.

HoverBot 2025 in Numbers: Weekly Releases, Three Verticals
HoverBot shipped 52 production releases in 2025, delivered 214 customer-facing features, and processed 12.4 million tokens as the product evolved from a generic chatbot widget into a configurable platform for Real Estate, SaaS, and Life Science use cases.