How chatbots remember: short term, long term and everything in between
What memory is and is not
Chatbots do not retain everything by default. Models operate within a finite context window. Once that window fills, older turns drop out. Anything worth carrying forward must be deliberately persisted by the application. Teams decide what to save, how long to keep it, and when to reuse it.
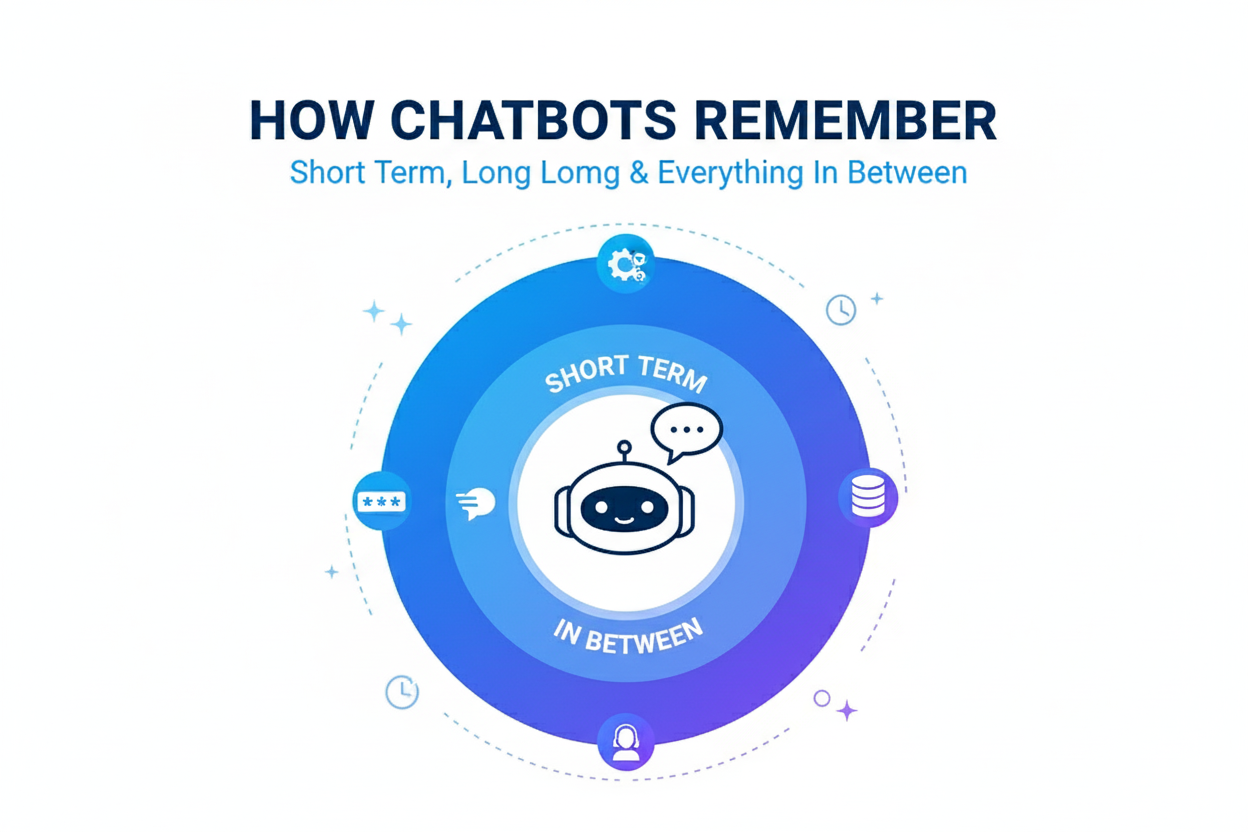
The four layer model
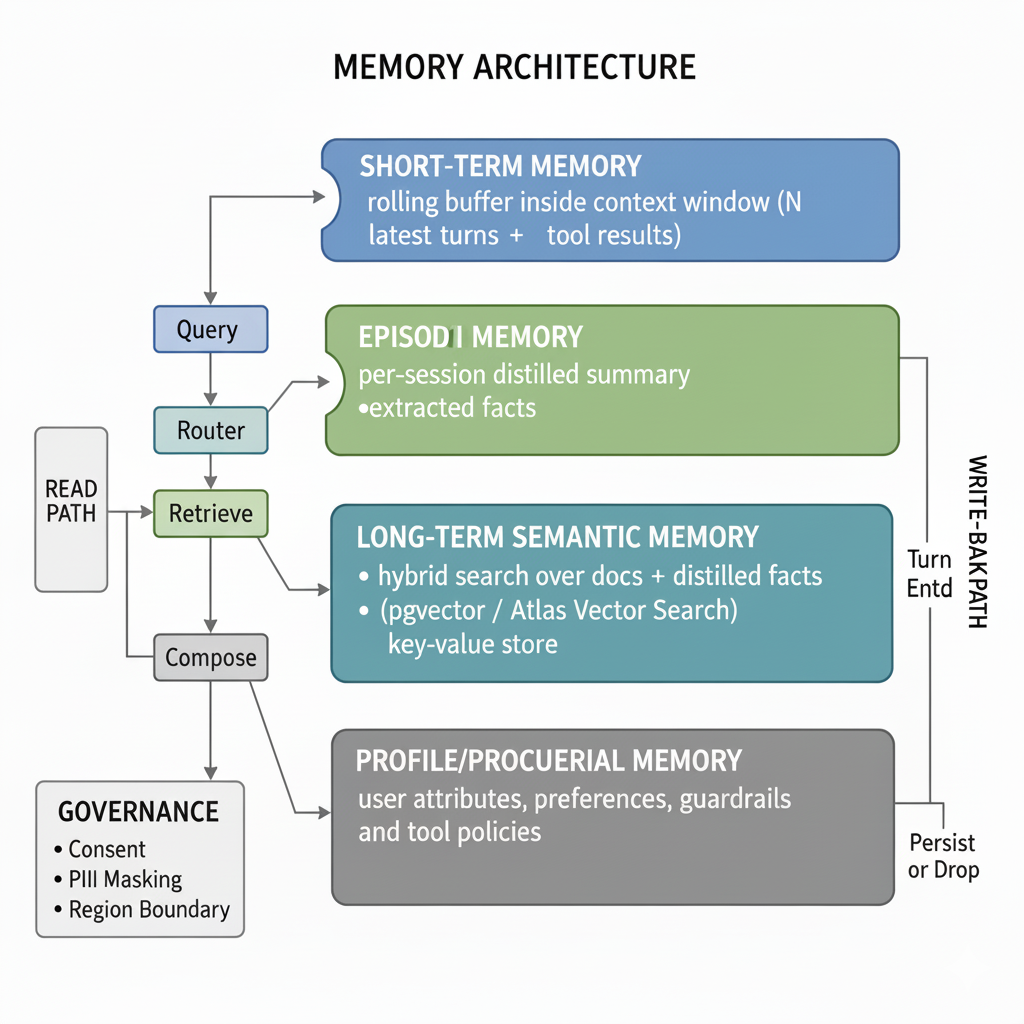
In production, memory behaves like a stack of cooperating layers. Short term memory is the working context. It is a rolling set of recent turns that sustains coherence but fades fast. Episodic memory captures each conversation as a concise session note with goals, decisions and open items so future sessions start informed without replaying everything. Long term memory stores durable facts and preferences, retrieved with a mix of keyword and semantic search. It is powerful and therefore selective and consent driven. Procedural memory holds rules and guardrails. These are standing instructions a bot must always follow. They are kept versioned and auditable rather than transient.
Short term memory: the working context
Short term memory is the rolling conversation window. It maintains coherence within a single session by keeping recent turns in the model's context. When the window fills, older exchanges drop out on a first-in-first-out basis. This layer handles immediate follow-ups, pronoun resolution, and topic continuity.
Design for short term memory is about context management. Keep the window large enough for natural conversation flow but small enough to avoid diluting important information. Include system messages and guardrails that must always be present. Use compression techniques for longer conversations, such as summarizing older turns while preserving key facts.
Episodic memory: session summaries
Episodic memory captures the essence of each conversation session. When a conversation ends, the system generates a structured summary containing the user's goals, decisions made, actions taken, and open items. This summary enables future sessions to start with context without replaying the entire conversation history.
Effective episodic memory focuses on outcomes rather than transcripts. Instead of storing "user asked about pricing then said thanks," store "user interested in enterprise plan, needs custom quote, follow up scheduled." This approach reduces storage costs and improves retrieval relevance.
Long term memory: durable facts and preferences
Long term memory persists user preferences, account details, and behavioral patterns across many sessions. This layer enables personalization and builds user trust through consistency. Retrieval combines keyword matching for exact facts with semantic search for related concepts.
Long term memory requires careful curation. Not every user statement deserves permanent storage. Focus on explicit preferences, confirmed facts, and repeated behaviors. Implement consent mechanisms and expiration policies. Tag entries with confidence levels and sources for later validation.
Procedural memory: rules and guardrails
Procedural memory contains the rules, policies, and guardrails that govern bot behavior. Unlike other memory types, procedural memory is not learned from user interactions but is explicitly configured and versioned. This includes safety rules, business policies, escalation triggers, and compliance requirements.
Procedural memory must be reliable and auditable. Version all rule changes, test them in staging environments, and maintain clear rollback procedures. These rules should be loaded fresh for each conversation to ensure consistency and prevent drift.
Design guidelines for production
Collect less by default. Persist only what moves outcomes. Avoid full transcripts without a legal need. Focus on actionable insights, confirmed preferences, and resolved decisions.
Gate write backs. Admit data only when relevant to likely future tasks, non sensitive, consented and tagged with a time to live.
Give users control. Provide a memory center to view, delete or disable. Enforce tenant and regional boundaries.
Budget tokens and time. Prevent short term context from crowding out rules or citations. Track p50 and p95 latency.
Log decisions. Record why an item was stored, which policy allowed it, and when it will expire or be revoked.
Scorecard to watch
- Recall accuracy on planted facts across sessions
- Harmful retention rate which should approach zero
- Deflection and first contact resolution lift
- Token and latency deltas at p50 and p95 after enabling memory
- User sentiment that it remembers me without feeling intrusive
HoverBot approach
HoverBot separates memory into layers and treats persistence as a governed workflow. Short term context keeps conversations fluent. Episodic notes accelerate follow ups. Long term items enter only with consent and time limits. Procedural rules remain versioned and testable. Customers can choose industry specific profiles that tighten defaults for regulated settings and can review or revoke stored items at any time through an admin console.
About the author
HoverBot TeamAI Product Engineering Team
Cross-functional team of AI engineers, product managers, and support operators building customer-facing chatbot systems in production environments. We ship weekly releases informed by production telemetry, closed-loop conversation reviews, and benchmark-driven evaluation cycles.
- Customer support automation and intelligent routing systems
- RAG pipeline design and guardrails for regulated workflows
- Operational analytics and closed-loop quality improvement
- Multilingual NLP and entity-level PII masking pipelines
- Production deployments across e-commerce, real estate, and SaaS verticals
Share this article
Related Articles
Routing Beats Bigger Models: A Production Architecture
GPT-4o costs 15x more than GPT-4o-mini. Claude Opus costs 30x more than Haiku. The question is not which model to use. The question is which model to use for each request. A smart router cuts cost 70% while improving quality.
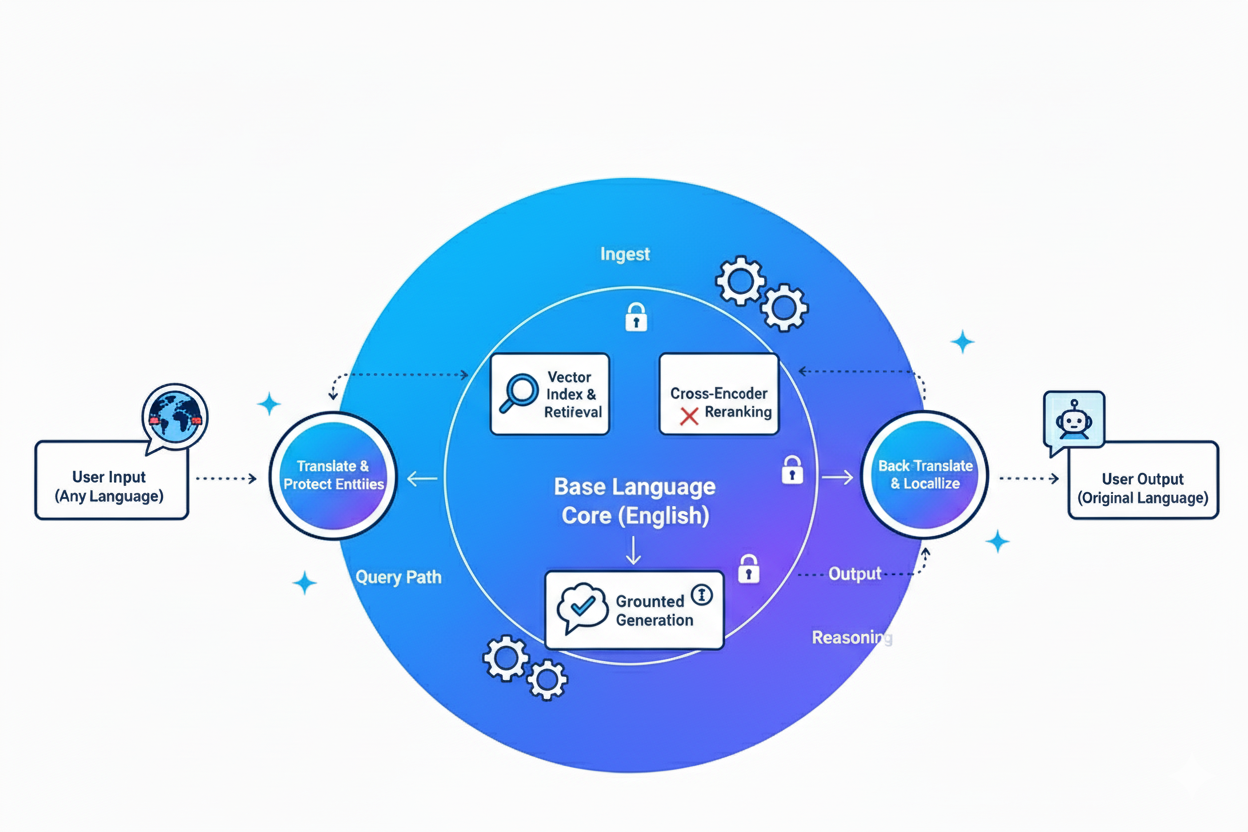
Multilingual RAG Architecture That Works in Production
A battle-tested architecture for multilingual RAG: translate at the edges, reason in one base language, and protect entities throughout. Includes chunking strategies for CJK scripts, embedding model benchmarks, and the metrics that matter.