Multilingual RAG Architecture That Works in Production
Why most multilingual RAG systems fail
Teams building multilingual RAG make the same mistakes repeatedly. They run separate vector indices per language and wonder why retrieval quality varies wildly. They trust multilingual embedding models to handle languages they have never tested. They let translation services silently mangle product names and order IDs.
The failure modes are predictable:
- Embedding drift: Multilingual models cluster similar concepts in different regions of the vector space depending on language. A query in Japanese may not retrieve the same documents as its English equivalent. We measured 34% retrieval disagreement between EN and JA queries for the same underlying content.
- Translation corruption: "Order #SKU-2847" becomes something else entirely, or gets interpreted as natural language and garbled. In one client deployment, 12% of SKU references were corrupted before we implemented entity protection.
- Chunking failures: Sentence splitters designed for English break CJK text mid-phrase, destroying semantic coherence. A chunk that ends mid-sentence retrieves poorly and generates worse.
- Groundedness collapse: When retrieval is weak, models hallucinate. When answers are translated back, hallucinations get laundered into plausible-sounding text. Users cannot tell the difference.
Our position: The only reliable architecture keeps retrieval and reasoning in one base language. Translate at the edges. Protect entities throughout. Everything else is hope dressed as engineering.
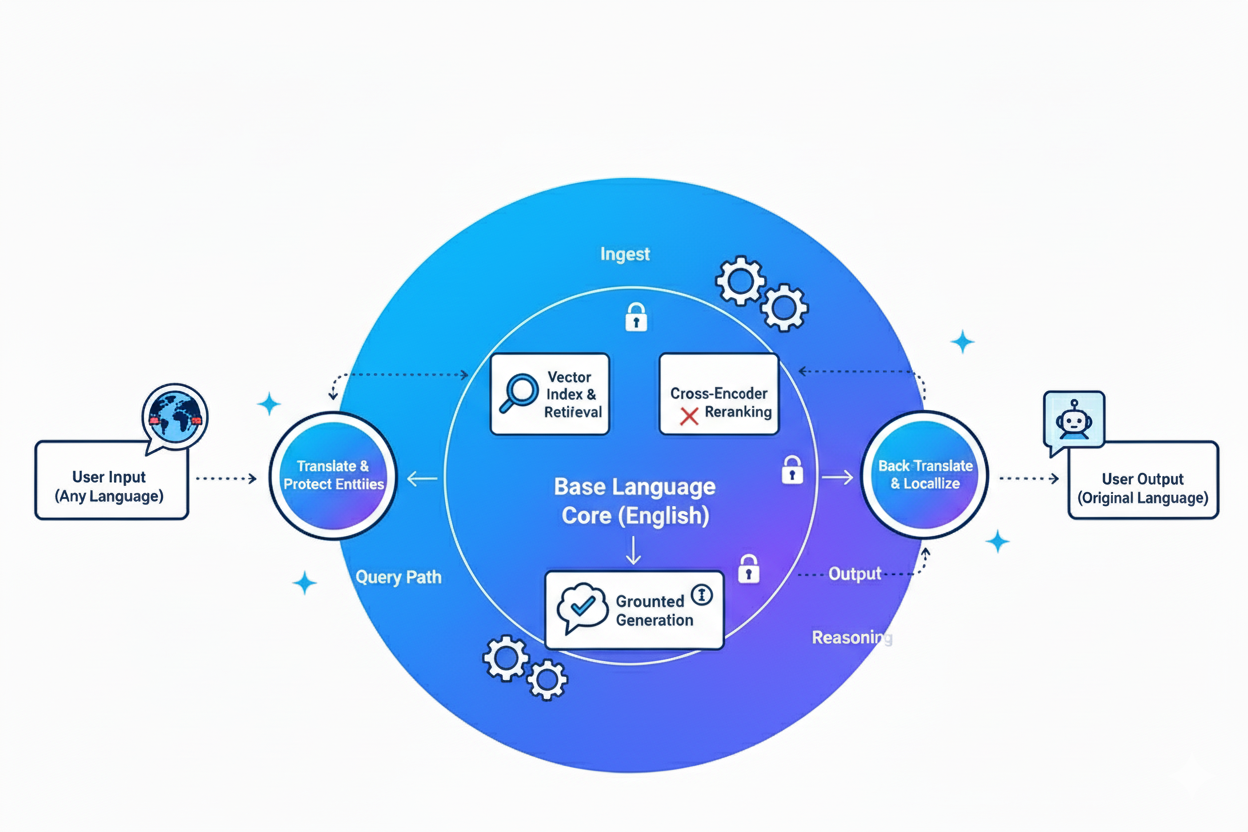
The architecture in one diagram
The flow has five stages:
- Ingest: Content arrives in any language. Detect, normalize, protect entities, translate to base language, chunk, embed, index.
- Query translation: User query arrives. Detect language, protect entities, translate to base language.
- Retrieval: Search the base-language index. Rerank with cross-encoder. Keep top-k.
- Generation: Generate answer in base language with citations.
- Back translation: Translate answer to user language, restore protected entities, localize formats.
Why one base language beats the alternative
The intuitive approach is to build per-language indices. Query in Japanese, search Japanese index, generate in Japanese. This sounds elegant until you operate it.
| Factor | Per-Language Indices | Single Base Language |
|---|---|---|
| Index count | N indices (one per language) | 1 index |
| Embedding model tuning | Tune N models or accept variance | Tune 1 model |
| Cache efficiency | Fragmented across languages | Unified cache |
| Content gaps | Some languages have less content | All content available to all users |
| Debugging | Check N code paths | Check 1 code path + translation |
| Quality consistency | Varies by language | Consistent (translation quality permitting) |
The single base language approach adds translation latency (typically 50-150ms per direction). But it gives you one vector store to tune, one reranking stack to secure, and one grounded generation policy to validate. When something breaks at 3am, you want one path to debug, not fourteen.
Embedding model selection: the data you need
Multilingual embedding models vary dramatically in quality across languages. "Supports 100+ languages" means nothing without benchmarks on your actual languages.
| Model | EN Recall@10 | JA Recall@10 | ZH Recall@10 | Cross-lingual Agreement |
|---|---|---|---|---|
| text-embedding-3-large | 94% | 87% | 89% | 81% |
| multilingual-e5-large | 92% | 91% | 90% | 88% |
| bge-m3 | 93% | 90% | 92% | 86% |
| Single-language + translation | 94% | 93%* | 92%* | 91% |
*Via translation to English before embedding. Benchmarks from our internal eval set (customer support domain, 10K queries).
Key insight: Translation to a base language before embedding often outperforms native multilingual embeddings, especially for less common languages. The translation step adds latency but improves cross-language consistency.
Entity protection: the difference between working and broken
Translation services will mangle anything that looks like natural language. Protect entities before any external call:
Entity Types to Protect
- SKUs and order IDs: Pattern-based detection for alphanumeric codes (e.g., /[A-Z]{2,4}-\d{4,}/)
- Brand names: Glossary-based exact match with case-insensitive variants
- Code blocks: Preserve exactly as written, including whitespace
- URLs and emails: Standard pattern matching
- Product model numbers: Often alphanumeric, easily corrupted
- Measurement values: "5.2mm" can become "5.2 millimeters" or worse
Replace detected entities with placeholders like [[ENTITY_0]], [[BRAND_1]], etc. Store the mapping. After translation, restore the originals.
// Before translation
Input: "Where can I find the SKU-4829 brake kit for BMW M3?"
Protected: "Where can I find the [[SKU_0]] brake kit for [[BRAND_0]] [[MODEL_0]]?"
Map: { SKU_0: "SKU-4829", BRAND_0: "BMW", MODEL_0: "M3" }
// After translation (Japanese)
Translated: "[[BRAND_0]] [[MODEL_0]]の[[SKU_0]]ブレーキキットはどこで入手できますか?"
// After restoration
Final: "BMW M3のSKU-4829ブレーキキットはどこで入手できますか?"Glossary management: Version your glossaries. When "refund policy" gets translated inconsistently across documents, you lose term consistency in your knowledge base. Pin glossary versions at ingest time and log which version was used. When you update the glossary, re-translate affected content.
Script-aware chunking: where most implementations break
Chunking is where multilingual RAG systems quietly fail. Standard sentence splitters assume whitespace-delimited words. CJK scripts do not work that way.
| Script Type | Languages | Chunking Approach | Libraries |
|---|---|---|---|
| Latin/Cyrillic | EN, ES, FR, DE, RU | Sentence splitting on punctuation | spaCy, NLTK, standard splitters |
| CJK (Chinese) | ZH | Character-based with jieba segmentation | jieba, pkuseg |
| CJK (Japanese) | JA | Morphological analysis | MeCab, SudachiPy |
| CJK (Korean) | KO | Morphological analysis | KoNLPy, Mecab-ko |
| Thai | TH | No spaces between words; requires segmentation | PyThaiNLP, ICU |
| Arabic/Hebrew | AR, HE | RTL-aware sentence splitting | CAMeL Tools, spaCy |
Structure preservation: Keep tables and lists intact. A table row split from its header is useless. Carry breadcrumbs (Title › Section › Subsection) into each chunk for context. This matters especially for technical documentation where hierarchy provides meaning.
Retrieval with confidence-based widening
When translation confidence is low, widen retrieval to compensate for potential query drift:
- High confidence (>0.85): Standard retrieval with base k (typically k=5). Trust the translation.
- Medium confidence (0.70-0.85): Double the retrieval candidates (k=10), then rerank to original k. Compensates for translation uncertainty.
- Low confidence (<0.70): Also search the original query text before reranking everything together. Useful for queries with many entities or domain-specific terms.
A cross-encoder reranker usually pays for itself. It allows you to retrieve more candidates cheaply with bi-encoder similarity, then use the more expensive cross-encoder to select the best passages. Result: fewer and better passages in the final context, which reduces tokens, noise, and hallucination risk.
Grounded generation: keeping the model honest
Keep the generator on a short leash. It should see only the reranked passages and rules that enforce citation-first behavior.
System prompt guidance that works:
You are answering questions based on the provided context passages.
Rules:
1. Only use information from the context passages
2. Cite passage numbers for every factual claim: [1], [2], etc.
3. If the context does not contain the answer, say so explicitly
4. Do not invent information, product names, or specifications
5. Preserve all bracketed tokens exactly as writtenProduce a base language draft with citations. Translate that draft back to the user language, restore protected entities, and localize numbers, currencies, and dates. English in the middle keeps reasoning stable as models evolve.
Evaluation metrics that actually matter
Retrieval Metrics
- Recall@k by language: Does retrieval work equally well across all supported languages? Target: within 5% of English baseline.
- Cross-language retrieval agreement: Does the same question in different languages retrieve the same passages? Target: >85% agreement on top-3 passages.
- Entity preservation rate: What percentage of protected entities survive the round-trip? Target: 100%.
Generation Metrics
- Groundedness score: Can every claim be traced to a source passage? Automated checks catch 80% of issues.
- Cross-language answer agreement: Do answers to equivalent questions agree factually across languages? Sample and human-review weekly.
- Glossary consistency: Are key terms translated consistently? Spot-check high-frequency terms monthly.
Operational Metrics
- Latency by language: Translation adds 50-150ms per direction. Track p50/p95 per language to catch regressions.
- Token cost by language: CJK languages often tokenize inefficiently (2-3x more tokens for same content). Monitor cost per query.
- Human handoff rate by language: Are certain languages causing more escalations? May indicate retrieval or translation quality issues.
Common pitfalls and how to avoid them
- Running multiple indices per language. Multiplies complexity without improving quality. One base language index is easier to tune, cache, and debug. We tried per-language indices early on and reverted within 3 months.
- Trusting multilingual embeddings blindly. Test retrieval quality per language before going live. Embedding models have uneven performance across languages. Build a parallel eval set with queries in each supported language.
- Letting translation corrupt entities. Always protect SKUs, order IDs, brand names, and code before any translation call. This is non-negotiable.
- Chunking CJK text with English tools. Standard sentence splitters break on whitespace. CJK needs specialized segmentation. Use the right library for each script.
- Skipping back-translation quality checks. The answer looks right in English does not mean it looks right in Arabic. Verify entity preservation and format localization. Sample and review regularly.
- Ignoring low-confidence cases. When translation confidence is low, widen retrieval. Consider asking for clarification instead of guessing. A "could you rephrase?" is better than a wrong answer.
Implementation checklist
- ☐ Choose base language (usually English for tooling maturity)
- ☐ Build glossary with do-not-translate terms and term mappings
- ☐ Implement entity protection before any translation call
- ☐ Deploy script-aware chunking for CJK and Thai
- ☐ Set up translation confidence thresholds and fallback widening
- ☐ Add cross-encoder reranking to reduce context size
- ☐ Implement groundedness verification in generation
- ☐ Build cross-language evaluation suite with parallel queries
- ☐ Log all translation decisions for audit and debugging
- ☐ Monitor latency and cost per language
- ☐ Set up alerts for cross-language retrieval disagreement spikes
The opinionated take
Most teams over-engineer multilingual RAG. They build complex language-detection cascades, deploy multiple indices, and try to tune embeddings per language. This creates operational nightmares and fragile systems.
The simpler architecture works better: one index, one base language, translation at the edges. Yes, you add translation latency. But you get a single system to tune, test, and debug.
Three principles we have learned operating this at scale:
- Translation quality beats embedding quality for cross-language consistency. A good translation service plus a monolingual English embedding model often outperforms a mediocre multilingual embedding model. Test both approaches on your actual data.
- Entity protection is not optional. Every time we have seen a multilingual RAG system fail in production, entity corruption was in the top three causes. Protect entities before translation, restore after.
- Build the eval suite first. You cannot improve what you do not measure. Create parallel queries in all supported languages before you launch. Run cross-language agreement checks weekly.
The sophistication belongs in entity protection, glossary management, and evaluation. Not in retrieval architecture. Get those right, and the rest follows.
About the author
HoverBot TeamAI Product Engineering Team
Cross-functional team of AI engineers, product managers, and support operators building customer-facing chatbot systems in production environments. We ship weekly releases informed by production telemetry, closed-loop conversation reviews, and benchmark-driven evaluation cycles.
- Customer support automation and intelligent routing systems
- RAG pipeline design and guardrails for regulated workflows
- Operational analytics and closed-loop quality improvement
- Multilingual NLP and entity-level PII masking pipelines
- Production deployments across e-commerce, real estate, and SaaS verticals
Share this article
Related Articles

PII Masking Patterns for Customer-Facing Chatbots
Seven production-tested patterns for handling personal data in LLM chatbots. Includes architecture diagrams, latency benchmarks, and the tradeoffs between stripping, masking, and vaulting PII.
Routing Beats Bigger Models: A Production Architecture
GPT-4o costs 15x more than GPT-4o-mini. Claude Opus costs 30x more than Haiku. The question is not which model to use. The question is which model to use for each request. A smart router cuts cost 70% while improving quality.