Knowledge Management for AI Chatbots: Structure, Maintain, Improve
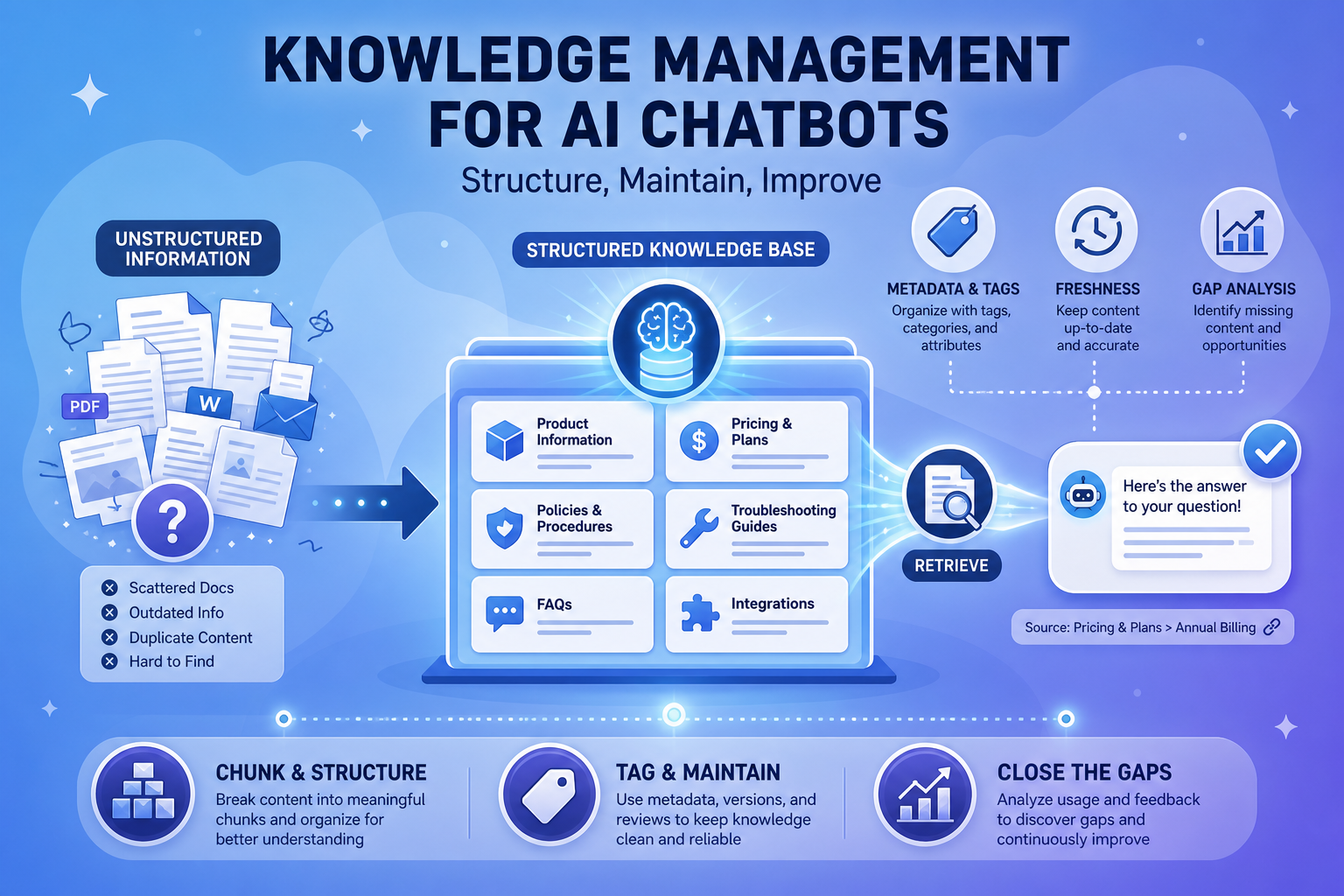
Most chatbot accuracy problems are not model problems. They are knowledge problems. The model can only be as good as what it retrieves, and what it retrieves is only as good as how you structured and maintained your knowledge base. Get this layer right and a mid-sized model outperforms a frontier model running on a mess.
Knowledge management for AI chatbots is the discipline of organizing, maintaining, and improving the content your assistant retrieves from. This guide covers how to structure content for retrieval-augmented generation (RAG), how to keep it fresh, and how to use analytics to find and close gaps systematically.
Why Knowledge Is the Real Bottleneck
In a RAG system, every answer flows through the same pipeline: the user's question is used to retrieve relevant chunks of your content, and the model composes an answer grounded in those chunks. If retrieval surfaces the wrong chunk, an outdated chunk, or no chunk at all, the answer suffers no matter how capable the model is.
This is good news, because knowledge is something you control directly. You cannot rewrite the model, but you can absolutely restructure your content so the right thing gets retrieved. For the broader architecture context, see multilingual RAG architecture.
Structure Content for Retrieval, Not Just Reading
Content written for humans browsing a help center is often poorly suited for retrieval. A few principles make a large difference:
- One topic per section. Self-contained sections retrieve cleanly; sprawling articles that cover five topics retrieve ambiguously.
- Front-load the answer. State the answer near the top of each section so a retrieved chunk carries the substance.
- Use explicit headings. Headings that mirror how customers phrase questions improve matching.
- Avoid pronoun chains across sections. A chunk should make sense on its own, without the paragraph before it.
Chunking Strategy: The Quiet Lever
Chunking decides what unit of content gets embedded and retrieved. Chunks that are too large dilute relevance and bury the answer; chunks that are too small lose the context needed to answer well. The sweet spot is usually a coherent section: large enough to stand alone, small enough to be specific.
Prefer structure-aware chunking that respects headings and natural boundaries over naive fixed-length splitting. Overlapping a little context between adjacent chunks helps preserve meaning at the edges. Then score retrieval at the chunk level so you can see which chunks actually answer questions and which never get used.
Metadata Tagging for Precision and Freshness
Metadata turns a flat pile of content into something you can filter and govern. Tag chunks with attributes like product area, audience, language, region, and last-reviewed date. This enables more precise retrieval, lets you scope answers to the right context, and makes freshness auditable.
A last-reviewed date in particular is the backbone of maintenance: it tells you and the system which content is aging and may need a human check before it keeps answering customers.
Maintain Freshness Without a Full-Time Librarian
Knowledge decays. Policies change, products ship, and yesterday's correct answer becomes today's complaint. The fix is a lightweight recurring process rather than a heroic annual cleanup:
- Flag content past its review date for a quick human check
- Tie knowledge updates to product and policy release cycles
- Retire or merge chunks that never get retrieved
- Promote answers that resolve well into canonical, well-structured entries
Use Analytics to Find Gaps Systematically
The most valuable signal in your chatbot is the question it could not answer. Cluster unresolved and low-confidence conversations to see exactly where the knowledge base has holes, then write targeted content to fill them. This closed-loop habit turns every miss into a specific, prioritized improvement rather than a vague sense that "the bot needs work." We covered the loop in depth in close the loop, and the analytics surface is described in the analytics deep dive.
A Weekly Maintenance Workflow
1. Review misses. Look at clustered unresolved and low-confidence conversations from the week.
2. Triage. Decide which gaps are worth fixing now based on volume and impact.
3. Write or restructure. Add or reshape content as self-contained, well-headed chunks.
4. Tag. Apply metadata and a fresh review date.
5. Verify. Confirm the new content actually gets retrieved for the target questions.
Thirty minutes a week of this beats a model upgrade for most teams. It is also what makes deflection and accuracy improve predictably rather than plateau.
Where HoverBot Fits
HoverBot is built around this discipline. It ingests and chunks your content for retrieval, scores relevance at the chunk level, and surfaces unresolved-intent clusters so you know exactly what to fix. The result is a chatbot management platform where knowledge quality is observable and improvable, not a black box. The knowledge-base tooling is detailed in the knowledge base management deep dive, with the wider system in the technical overview.
Want to see grounded retrieval and gap analytics on your own content? Request a demo and watch HoverBot answer from your knowledge base.
Request a demoAbout the author
HoverBot TeamAI Product Engineering Team
Cross-functional team of AI engineers, product managers, and support operators building customer-facing chatbot systems in production environments. We ship weekly releases informed by production telemetry, closed-loop conversation reviews, and benchmark-driven evaluation cycles.
- Customer support automation and intelligent routing systems
- RAG pipeline design and guardrails for regulated workflows
- Operational analytics and closed-loop quality improvement
- Multilingual NLP and entity-level PII masking pipelines
- Production deployments across e-commerce, real estate, and SaaS verticals
Share this article
Related Articles
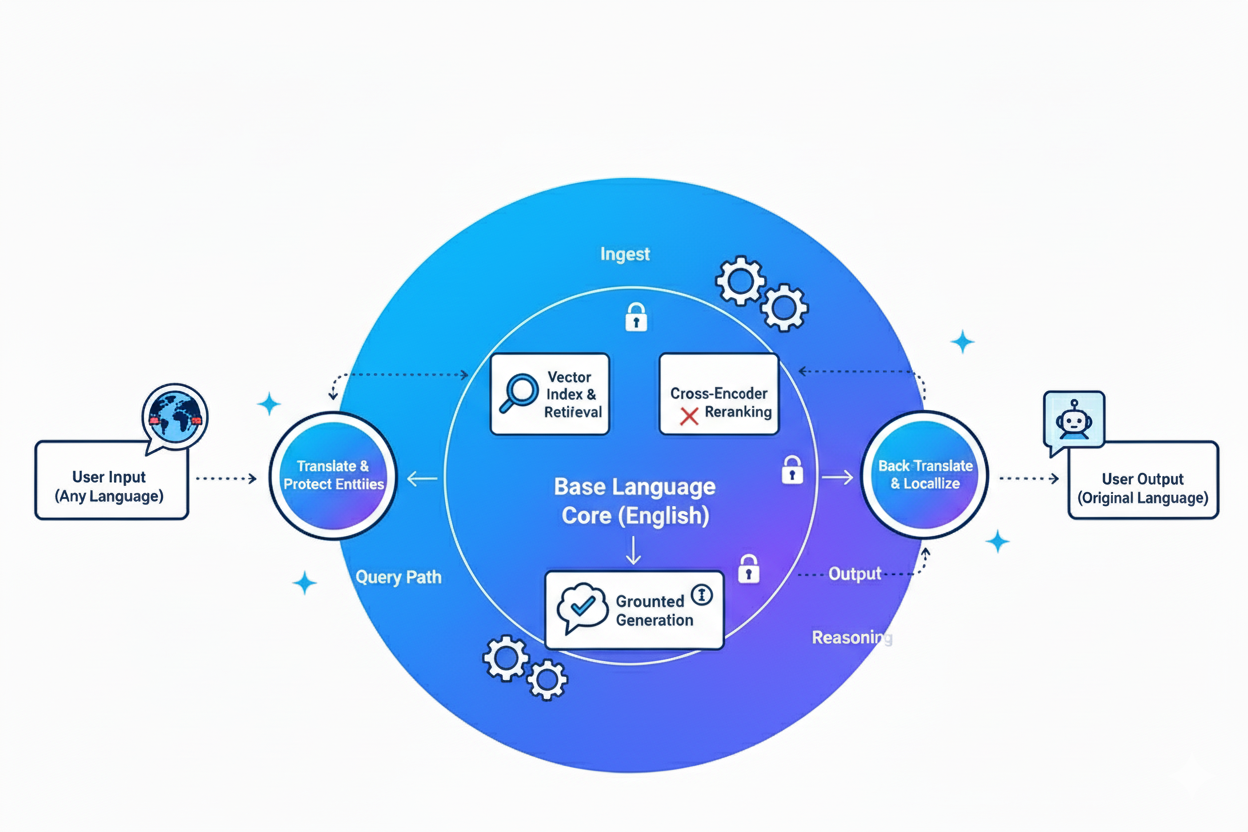
Multilingual RAG Architecture That Works in Production
A battle-tested architecture for multilingual RAG: translate at the edges, reason in one base language, and protect entities throughout. Includes chunking strategies for CJK scripts, embedding model benchmarks, and the metrics that matter.
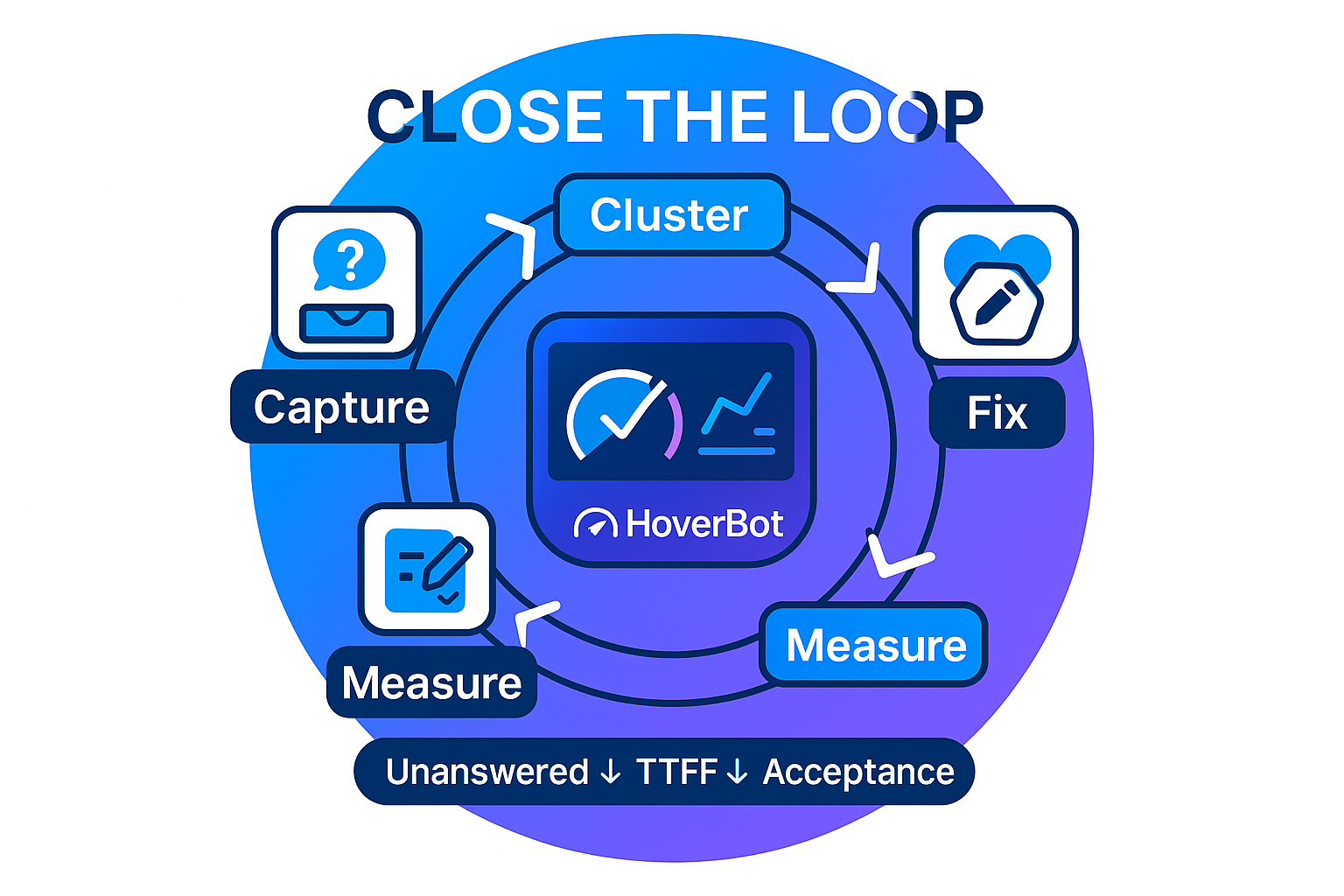
Close the loop: analytics that teach your chatbot to fix itself
Many chatbots stall for the same reason. Unanswered questions build up and nothing changes. Learn how to capture every miss as a signal, turn real gaps into small updates, and run a weekly improvement loop that delivers results without bigger models.